pytorch 的自动求导功能简介
自动求导是 pytorch 的一项重要功能,它使得 pytorch 能够灵活快速地构建神经网络模型。反向传播算法是优化神经网络模型参数的一个重要方法,在反向传播过程中需要不断计算损失函数对参数的导数,然后更新相应的模型参数,首先简单介绍一下反向传播算法。
一、反向传播算法简介
这部分的主要参考资料来自这里:https://www.cnblogs.com/charlotte77/p/5629865.html,原文的计算过程非常详细,有需要可以去阅读原文,另外原文中有一处疏漏之处,就是也需要计算损失函数对偏置量、的导数并且更新偏置量。
回到正题,对于一个典型的神经网络模型,如下所示:
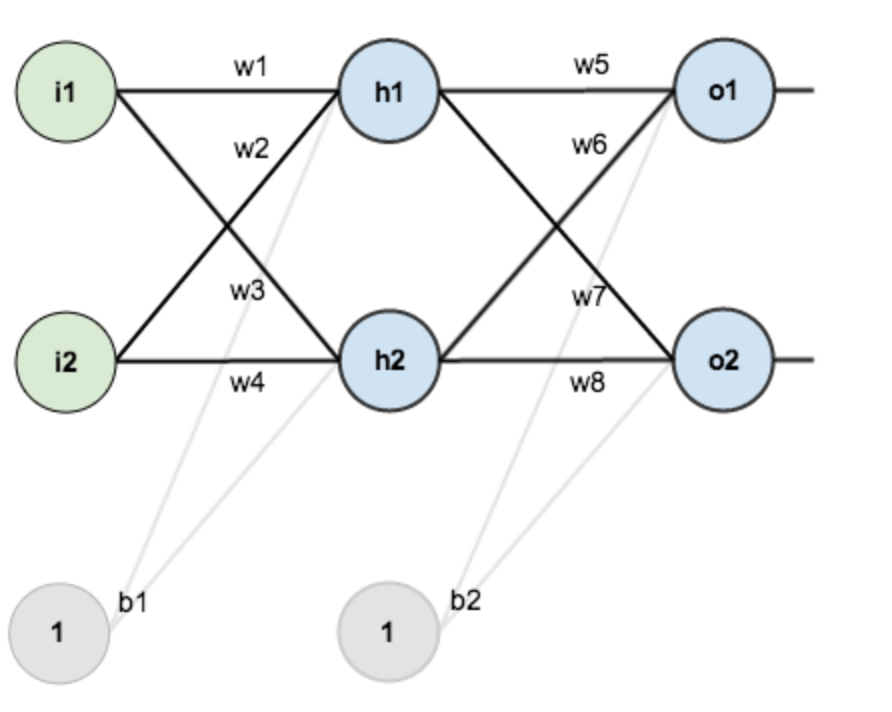
我们可以将它看作是一个映射(),即是从输入向量到输出向量之间的映射,而这个映射关系完全是由网络的连接关系和w1-w8、b1、b2这些参数决定的。在模型的训练过程中,输入和输出数据是固定的,我们要做的是调节这些控制参数来使得通过神经网络计算的输出与实际输出的误差达到最小,误差的具体形式通过损失函数()来定义,由于输入和输出数据是固定的,同时在网络结构固定的情况下,损失函数()仅是w1-w8、b1、b2这些控制参数的函数,神经网络的优化过程用公式表达就是:
反向传播过程就是通过不断计算损失函数()对w1-w8、b1、b2这些控制参数的导数,根据梯度下降法的原理,更新参数,使得损失函数()向着减小的方向优化,优化完成即代表损失函数达到最小。
需要注意的一点是,在网络参数优化过程中,我们是通过损失函数()对控制参数求梯度来优化的,而不是通过网络模型()对控制参数求梯度,损失函数()是一个标量函数,而网络模型()通常是一个向量函数,我们说的求梯度是对多变量的标量函数求梯度,参数的更新方法用公式可以表达为:
其中为学习率。
一个完整的神经网络训练过程可以总结以下两步循环进行:
- 前向传播:计算在当前参数下,带入输入数据后模型的输出
- 反向传播:计算损失函数对网络各个控制参数的梯度,然后更新控制参数。这里要注意的是由于一些参数前后有耦合关系,因此在某些求导中需要用到链式法则。
二、pytorch 的自动求导功能
pytorch 能够自动求导,这为构建神经网络提供了很大的方便。以下的内容大部分都翻译自 pytorch 官方的内容:https://pytorch.org/tutorials/beginner/introyt/autogradyt_tutorial.html,部分有所改动,以官网为准。
1. 前言
pytorch 的自动求导特征使得其能够快速灵活地构建机器学习项目,在复杂的计算中它能够快速且容易地计算多变量偏导数(梯度),在基于反向传播的神经网络模型中这一操作是核心。
pytorch 的自动求导能力来自于在程序运行过程中,它会动态地追踪你的计算,这意味着如果你的模型有条件分支,或者循环的步数在程序运行之前是未知的,它同样能够正确地追踪计算,你能够得到正确的结果来继续学习过程,所有的这些,结合你建立在 python 之上的模型,相比于传统的用于计算梯度的固定结构,能够提供一个更加灵活的框架。
2. 我们需要自动求导机制做什么
机器学习模型是一个有输入和输出的函数,在这个讨论中,我们将把输入看作是一个i维的向量,其中的元素写作。我们可以把模型写作M,它是关于输入的一个向量函数:(这里我们把M的输出值看作是一个向量是因为总的来说,一个模型可以有任意数量的输出)。
由于接下来我们将主要讨论在训练过程中的自动求导过程,所以我们对输出的兴趣主要集中在模型的损失上,损失函数是关于模型输出的标量函数,这个函数表示的是针对特定输入我们模型的输出与理想输出的差别多大。注意:在这以后,我们将会在上下文提示清楚的地方省略向量符号,例如写而不是。
在训练模型的过程中,我们想要最小化损失函数,对于一个完美模型的理想情况是调节它的学习权重——即是调节函数的参数使得针对所有的输入模型的损失是0,在真实世界中,它意味着我们需要一步步地轻微改变学习权重,反复迭代直到对于大部分的输入我们都能获得一个可以容忍的损失。
那么我们要如何决定权重离理想值多远以及优化的权重的方向呢?我们想要最小化损失,这意味着使它对输入的一阶导数为0,即是:。
不过,回想一下,损失不是直接从输入中得出的,而是模型输出的函数(模型输出是输入的直接函数),即,根据微积分的链式求导法则,有:,其中会使计算变得复杂。这一项表示的是模型的输出相对于输入的偏导数,如果我们根据链式法则扩展这一表达式,将会涉及到模型中每个相乘的学习权重,每个激活函数,以及每个其它数学变换的局部偏导数。每个变量的偏导数的完整表达式是计算图中我们试图计算变量的每条可能路径上变量的局部偏导数的乘积之和。
特别地,我们对学习权重的梯度非常感兴趣——因为它们告诉我们使得损失函数更接近0的学习权重的优化方向。
由于这些局部导数(每个对应于模型计算图中的单独路径)的数量将随着神经网络的深度呈指数增长,计算它们的复杂度也会相应增加。这就是自动求导产生的原因:它会追踪每次计算的历史,pytorch 模型中每个计算张量都有它的输入张量的历史纪录以及用于创建它的函数,结合 pytorch 中每个作用于张量的函数都有一个内置的实现来计算它们的导数,这样大大加快了学习所需的局部导数的计算过程。
3. 一个简单的例子
(这部分内容参考官网,但有所改动)
这里我们简单地利用 pytorch 的自动求导机制来计算函数 在一个周期上的导数,代码如下:
1 | import torch |
结果如下图所示:
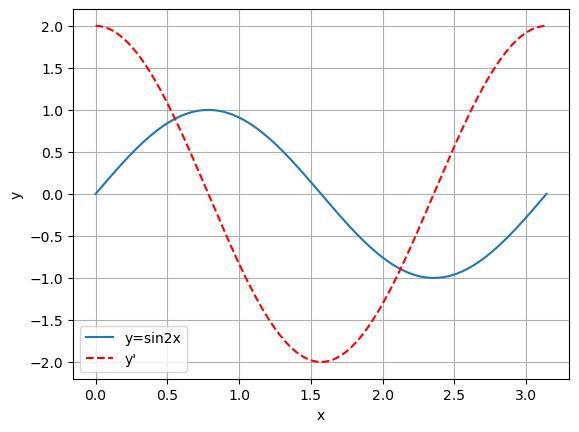
这里我们可以来分析一下实现自动求导的具体过程,首先需要定义需要求导的自变量,例如上面例子中显然 x 为需要求导的自变量,然后是始终要记住:要使用标量函数对自变量求导,而不是矢量函数。例如上面中我们求出的 y 是矢量函数,而不是标量函数,因此首先需要用 out=y.sum() 语句,转换成标量函数,用公式表示就是:
然后运行 out.backward() 语句即可完成反向传播求导过程。
4. 模型训练过程中使用自动求导(略)
5. 关闭和打开自动求导
在某些情况下,你需要对是否进行自动求导进行精确控制,有多种方法可以做到这一点,视情况而定,最简单的方法是直接通过改变 requires_grad 参数来控制:
1 | a = torch.ones(2, 3, requires_grad=True) |
上述方法会永久关闭自变量的自动求导过程,如果你只是想要暂时关闭自动求导过程,可以使用 torch.no_grad():
1 | a = torch.ones(2, 3, requires_grad=True) * 2 |
另外,值得一提的是,torch.no_grad() 也可以用作函数装饰器,用该装饰器装饰的函数,输出的变量不能自动求导。
最后,你可能有一个需要追踪计算导数的张量,但是你需要一个不能计算导数的备份。对于这一要求,Tensor 对象有 detach 方法,它可以创建一个原来张量的备份,但是不保存计算历史。
当我们想要绘制一些张量时,我们需要这么做,这是因为 matplotlib 需要一个 numpy 数组作为输入,但是对于具有 requires_grad = True 的张量,不能实现从 pytorch 张量到 numpy 数组的隐式转换。在这种情况下,需要使用 detach 产生的不保存计算历史的张量。
6. 自动求导和原地替换操作
原地替换操作是指函数运行完成后,会用输出值替换掉输入变量的值,例如语句:
1 | x = torch.sin(2.0*x) |
这就是一个原地替换操作。在之前的例子中,我们都会新建变量来保存计算过程中的中间变量,自动求导需要这些中间变量来进行梯度计算,由于这个原因,当要使用自动求导时,你必须小心使用原地替换操作,因为这样可能会销毁你在 backward() 求导时需要用到的信息,当你对需要自动求导的网络中的叶变量使用原地替换操作时,pytorch 将会停止运行,如下:
1 | a = torch.linspace(0, 2.0*torch.pi, steps=25, requires_grad=True) |
运行之后改代码会抛出 runtime error 错误,这里 sin_() 函数就是一个原地替换操作,会把计算结果直接赋给 a 变量,从而导致错误。
7. 自动求导的性能分析器(略)
8. 高阶话题:关于自动求导更多的细节
如果你有一个n维输入m维输出的函数,,完整的梯度是每个输出相对于每个输入的偏导数矩阵,也叫做雅可比矩阵:
如果你有第二个函数,,其输入为m维向量(与上面函数的输出维度相同),其输出值为一个标量,那么你就可以将它对的梯度表示为一个列向量,即是——即是只有一列的雅可比矩阵。
更具体地说,将第一个函数想象为神经网络模型(可能有许多输入和输出),将第二个函数想象为损失函数(模型的输出作为输入,损失值作为标量输出)。
如果我们将第一个函数的雅可比矩阵乘以第二个函数的梯度,并应用链式法则,得到:
计算得到的列向量是第二个函数相对于第一个函数输入的梯度——或者在我们的模型和损失函数情况下,损失函数对模型输入的梯度。
torch.autograd就是计算这些乘积的引擎,这就是我们在反向传播过程中如何累积学习权重的梯度。
因此,backward() 函数也可以将向量作为传入参数来调用,计算结果为该输入向量与自动求导计算的雅可比矩阵的乘积,让我们通过一个特定例子来看下:
1 | x = torch.randn(3, requires_grad=True) |
结果为:
tensor([2.0480e+02, 2.0480e+03, 2.0480e-01])
上面代码中 backward() 函数将向量 v 作为输入参数,实际计算中就相当于用 y 对 x 求梯度产生的雅可比矩阵的转置()来乘以,计算结果与以下代码的结果等价:
1 | x = torch.randn(3, requires_grad=True) |
此处在 backward() 函数中并没有传入参数,而是定义了损失函数,用公式表达为:
9. 高级 API
在 autograd 上有一个 API,可以让你直接访问重要的微分矩阵和向量运算,特别地,它允许你计算特定函数在特定输入下的雅可比矩阵和海森矩阵(海森矩阵和雅可比矩阵类似,但表示的是完整的二阶偏导数)。它还提供了获取这些矩阵向量积的方法:
- torch.autograd.functional.jacobian():计算给定输入下函数的雅可比矩阵
- torch.autograd.functional.hessian():计算给定输入下函数的海森矩阵
- 更多的高级 API 可以参考官方文档:https://pytorch.org/docs/stable/autograd.html#functional-higher-level-api